TermTerm is the basic unit to form a document or a piece of message. Term is releted to domain the application is designed for and languages. Take Chinese for an example, 道德经 is a book, itself is term, while 道德,经 are two seperate terms too. A statement might consist of a collection of words which means nothing or different thing when seperates them into words or characters. For example, an organization's name typically is not a sequence of terms related to the domain. in this case, tagging mechanism is required to improve the search performance.
Vector Space Model (VSM)Let t[i] (1<=i<=M) and d[j] (1<=j<=N) represent a term and a document in the database, where M is the number of terms and N is the number of documents. In the VSM,
a document d(j) is represented as a M dimensional vector
d[j]=(w[1,j], ..., w[M,j]) where w[i,j] is a weight of term t[i] in a document d[j].
A query is represented as q[k]=(w[1,k],....,w[i,k], ...., w[M,k]), 1<=k<=L, where w[i,k] is a weight of a term t[i] in a query q[k].
These weights are computed by the standard normalized tf*idf weighting scheme as follows:
w[i,j]=tf[i,j]*idf[i]. where tf[i,j] is the weight calculated using the term frequencey f[i,j] and idf[i] is the weight is weight calculated using the inverse of the document frequency (?).
The result of the retrieval is represented as a list of documents ranked according to their similarity to the query. The similiarity sim(d[j], q[k]) between a document d[j] and a query q[k] is measured by the standard cosine of the angle between d[j] and q[k]:
sim(d[j], q[k])=d[j] x q[k]/(||d[j]||*||q[k]||).
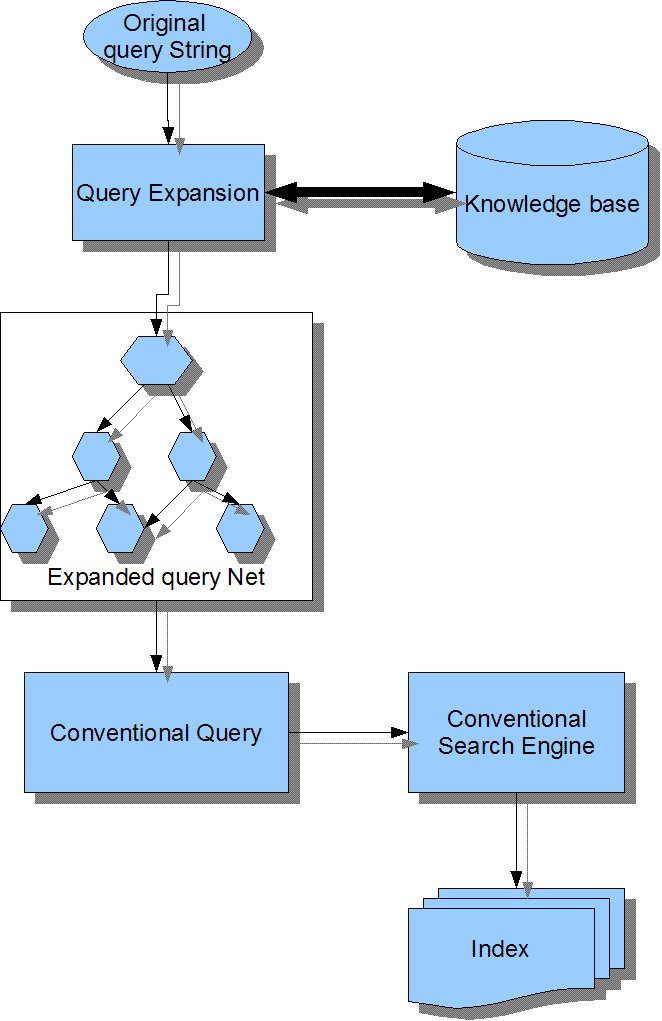
A problem of the standard VSM is that a query is often too short to rank documents appropriately, to cope with this problem, query expansion mechanism could be applied.